
Kafka3.7.0:4.Kafka集群
Kafka集群搭建
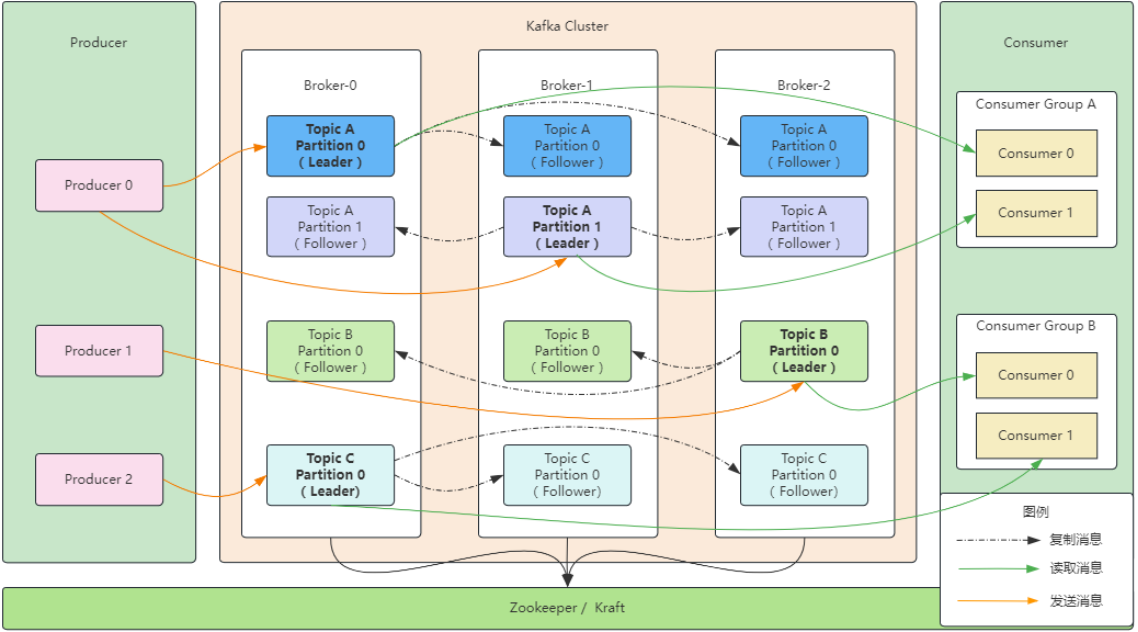
Kafka集群搭建方式
- 基于Zookeeper的集群搭建方式
- 基于Kraft的集群搭建方式
基于Zookeeper的集群搭建
- 解压三个kafka
- 配置kafka集群:server.properties
- 集群启动并测试
解压
1 | tar -zxvf kafka_2.13-3.7.0.tgz # 解压 |
配置kafka集群
配置kafka集群:server.properties
- 三台分别配置为:
broker.id=1、broker.id=2、broker.id=3
1 | cd kafka-01/config |
其他2个同理。
该配置项是每个broker的唯一id,取值在0~255之间
- 三台分别配置listener=PAINTEXT:IP:PORT
1 | listeners=PLAINTEXT://0.0.0.0:9091 |
三台分别配置advertised.listeners=PAINTEXT:IP:PORT
1 | advertised.listeners=PLAINTEXT://192.168.1.7:9091 # 请换成你的ip |
- 配置日志目录
1 | log.dirs=/tmp/kafka-logs-9091 |
这是极为重要的配置项,kafka所有数据就是写入这个目录下的磁盘文件中的;
- 配置zookeeper连接地址
1 | zookeeper.connect=localhost:2181 |
如果zookeeper是集群,则:
1 | zookeeper.connect=localhost:2181,localhost:2182,localhost:2183 |
启动测试
- 启动Zookeeper,切换到bin目录:
./zkServer.sh start

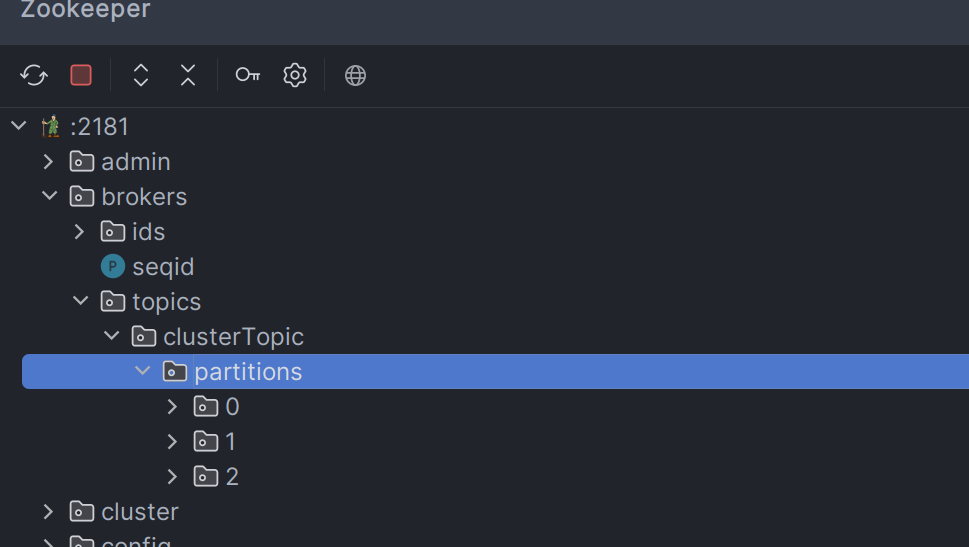
连接测试(这里使用IDEA插件ZookeeperManager):
- 启动三个Kafka,切换到bin目录:
./kafka-server-start.sh ../config/server.properties
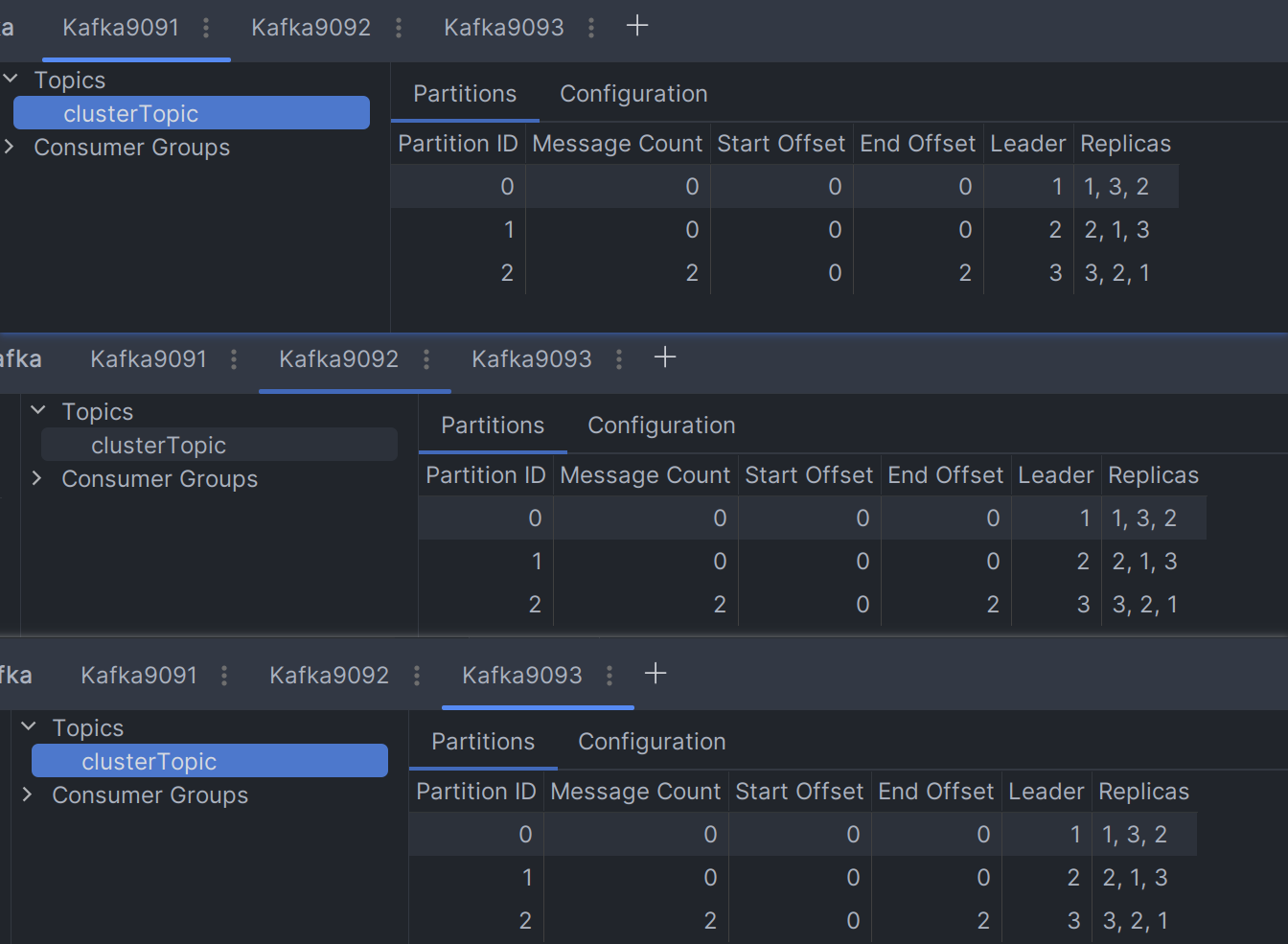
连接测试(IDEA插件Kafka):
其他2个同理。
查看zookeeper:
- 查看topic详情:
./kafka-topics.sh --bootstrap-server 127.0.0.1:9091 --describe --topic clusterTopic
SpringBoot连接Kafka集群
在之前的项目上CV一份最新的module
修改项目配置文件:
1 | spring: |
Kafka配置多副本:
1 |
|
启动程序(请先注释掉@KafkaListener,或者先删除消费者代码)
生产者:
1 |
|
编写测试方法发送消息:
消费者:
1 |
|
运行主程序:

主副本究竟放在哪个broker中是由kafka内部机制决定的
从副本和主副本不在同一个broker上
Kafka12个核心概念
- 服务器 broker
- 主题 topic
- 事件 Event (message、消息、数据)
- 生产者 producer
- 消费者 consumer
- 消费组 consumer group
- 分区 partition
- 偏移量offset(生产者偏移量,消费者偏移量)
- Replica副本:分为 Leader Replica 和 Follower Replica;
- ISR副本:在同步中的副本 (In-Sync Replicas)
- LEO:日志末端偏移量 (Log End Offset)
- HW:高水位值 (High Water mark)
前9个我们之前已经讲过了,这里我们只讲后面3个。
ISR副本
什么是ISR副本
ISR副本:在同步中的副本 (In-Sync Replicas),包含了Leader副本和所有与Leader副本保持同步的Follower副本。
写请求首先由 Leader 副本处理,之后 Follower 副本会从 Leader 上拉取写入的消息,这个过程会有一定的延迟,导致 Follower 副本中保存的消息略少于 Leader 副本,但是只要没有超出阈值都可以容忍,但是如果一个Follower 副本出现异常,比如宕机、网络断开等原因长时间没有同步到消息,那这个时候,Leader就会把它踢出去,Kafka 通过ISR集合来维护一个"可用且消息量与Leader相差不多的副本集合,它是整个副本集合的一个子集"。
成为ISR副本的条件
在Kafka中,一个副本要成为ISR(In-Sync Replicas)副本,需要满足一定条件:
- Leader副本本身就是一个ISR副本
- Follower副本最后一条消息的offset与Leader副本的最后一条消息的offset之间的差值不能超过指定的阈值,超过阈值则该Follower副本将会从ISR列表中剔除
replica.lag.time.max.ms:默认是30秒;如果该Follower在此时间间隔内一直没有追上过Leader副本的所有消息,则该Follower副本就会被剔除ISR列表replica.lag.max.messages:落后了多少条消息时,该Follower副本就会被剔除ISR列表,该配置参数现在在新版本的Kafka已经过时了
LEO
LEO:日志末端偏移量 (Log End Offset),记录该副本消息日志(log)中下一条消息的偏移量,注意是下一条消息,也就是说,如果LEO=10,那么表示该副本只保存了偏移量值是[0, 9]的10条消息
HW
HW:(High Watermark),即高水位值,它代表一个偏移量offset信息,表示消息的复制进度,也就是消息已经成功复制到哪个位置了。即在HW之前的所有消息都已经被成功写入副本中并且可以在所有的副本中找到,因此,消费者可以安全地消费这些已成功复制的消息。
对于同一个副本而言,小于等于HW值的所有消息都被认为是“已备份”的(replicated),消费者只能拉取到这个offset之前的消息,确保了数据的可靠性。
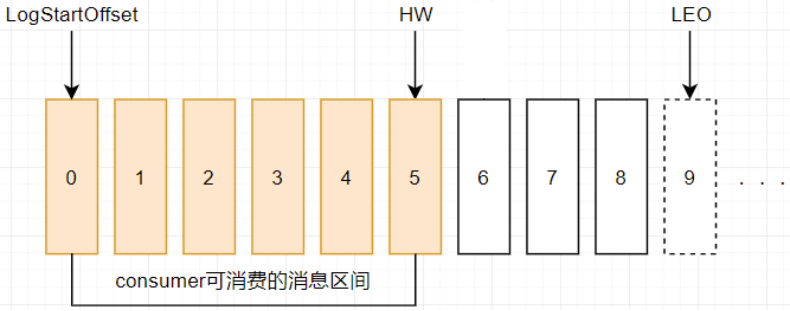
ISR、HW、LEO的关系
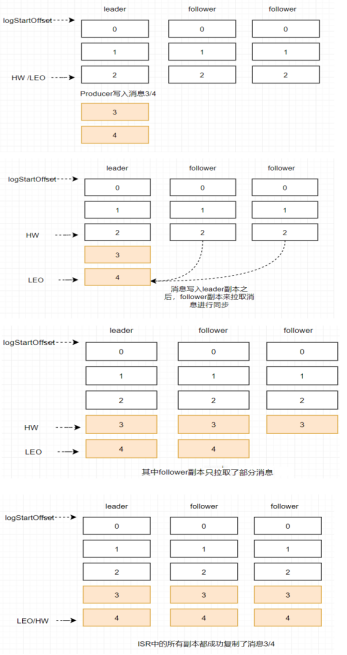
基于KRaft的集群搭建
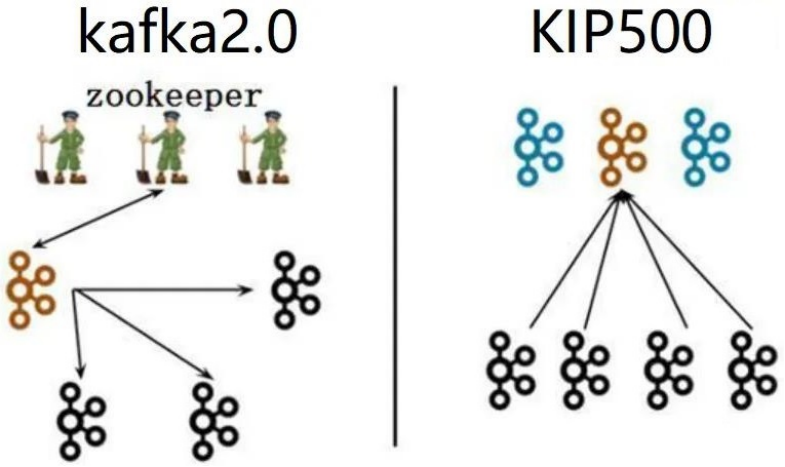
Controller节点在Kafka集群中扮演着管理和协调的角色,管理整个集群中所有分区和副本的状态,当某个分区的leader副本出现故障时,Controller负责为该分区选举新的leader副本。
Broker节点在Kafka集群中主要承担消息存储和转发等任务。
左图:
- 集群有三个节点都是Broker角色,其中一个Broker(褐色)是Controller控制器节点,控制器节点将集群元数据信息(比如主题分类、消费进度等)保存到zookeeper,用于集群各节点之间分布式交互。
右图:
- 一个集群有四个Broker节点,人为指定其中三个作为Conreoller角色(蓝色),从三个Controller中选举出一个Controller作为主控制器(褐色),其它2个备用,Zookeeper不再被需要,相关的元数据信息以kafka日志的形式存在(即:以消息队列消息的形式存在)。
Kafka服务器规划
- ip=192.168.11.129:9091 roles=broker,controller node.id=1
- ip=192.168.11.129:9092 roles=broker,controller node.id=2
- ip=192.168.11.129:9093 roles=broker,controller node.id=3
基于KRaft的集群搭建方式:
- 准备三个Kafka,解压三个Kafka
- 配置kafka集群:config/kraft/server.properties
- 集群启动并测试
解压
1 | tar -zxvf kafka_2.13-3.7.0.tgz # 解压 |
配置kafka集群
配置kafka集群:config/kraft/server.properties
- 三台分别配置:
1 | cd kafka-01/config/kraft |
修改配置,其他2个kafka同理。
1 | broker.id=1 |
- 三台分别配置节点角色:
1 | process.roles=broker,controller # 默认 |
- 三台分别配置参与投票的节点
1 | controller.quorum.voters=1@192.168.1.7:9081,2@192.168.1.7:9082,3@192.168.1.7:9083 # 只本机可以使用localhost |
- 三台配置各自监听本机的ip和端口
1 | listeners=PLAINTEXT://0.0.0.0:9091,CONTROLLER://0.0.0.0:9081 |
- 三台配置对外开放访问的ip和端口
1 | advertised.listeners=PLAINTEXT://192.168.1.7:9091 |
- 三台分别配置日志目录
1 | log.dirs=/tmp/kraft-combined-logs-9091 |
启动测试
进入kafka的bin目录下:
- 生成Cluster UUID(集群UUID):
./kafka-storage.sh random-uuid(只在一台机器上生成,其他共用) - 格式化日志目录:
./kafka-storage.sh format -t 生成的UUID -c ../config/kraft/server.properties(每个kafka都要执行) - 启动Kafka:
./kafka-server-start.sh ../config/kraft/server.properties &(每个kafka都要执行) - 关闭Kafka:
./kafka-server-stop.sh ../config/kraft/server.properties(每个kafka都要执行)







