
Scikit-Learn
多种多样的机器学习
通常来说, 机器学习的方法包括:
- 监督学习 supervised learning;
- 非监督学习 unsupervised learning;
- 半监督学习 semi-supervised learning;
- 强化学习 reinforcement learning;
- 遗传算法 genetic algorithm.
pip 安装
安装 Scikit-learn (sklearn) 最简单的方法就是使用 pip 安装它.
首先确认自己电脑中有安装
Python (>=2.6 或 >=3.3 版本) Numpy (>=1.6.1) Scipy (>=0.9)
然后找到你的 Terminal (MacOS or Linux), 或者 CMD (Windows). 输入以下语句:
1 | # python 2+ 版本复制: |
看图选方法
安装完 Sklearn 后,不要直接去用,先了解一下都有什么模型方法,然后选择适当的方法,来达到你的目标。
Sklearn 官网提供了一个流程图, 蓝色圆圈内是判断条件,绿色方框内是可以选择的算法:
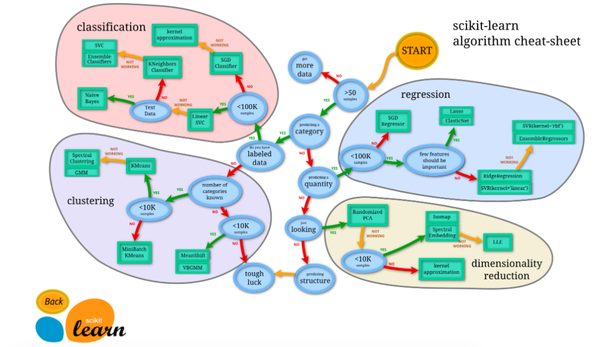
从 START 开始,首先看数据的样本是否 >50,小于则需要收集更多的数据。
由图中,可以看到算法有四类,分类,回归,聚类,降维。
其中 分类和回归是监督式学习,即每个数据对应一个 label。 聚类 是非监督式学习,即没有 label。 另外一类是 降维,当数据集有很多很多属性的时候,可以通过 降维 算法把属性归纳起来。例如 20 个属性只变成 2 个,注意,这不是挑出 2 个,而是压缩成为 2 个,它们集合了 20 个属性的所有特征,相当于把重要的信息提取的更好,不重要的信息就不要了。
然后看问题属于哪一类问题,是分类还是回归,还是聚类,就选择相应的算法。 当然还要考虑数据的大小,例如 100K 是一个阈值。
可以发现有些方法是既可以作为分类,也可以作为回归,例如 SGD。
通用学习模式
要点
Sklearn 把所有机器学习的模式整合统一起来了,学会了一个模式就可以通吃其他不同类型的学习模式。
例如,分类器,
Sklearn 本身就有很多数据库,可以用来练习。 以 Iris 的数据为例,这种花有四个属性,花瓣的长宽,茎的长宽,根据这些属性把花分为三类。
我们要用 分类器 去把四种类型的花分开。
今天用 KNN classifier,就是选择几个临近点,综合它们做个平均来作为预测值。
导入模块
1 | from sklearn import datasets |
创建数据
加载 iris 的数据,把属性存在 X,类别标签存在 y:
1 | iris = datasets.load_iris() |
观察一下数据集,X 有四个属性,y 有 0,1,2 三类:
1 | print(iris_X[:2, :]) |
把数据集分为训练集和测试集,其中 test_size=0.3,即测试集占总数据的 30%:
1 | X_train, X_test, y_train, y_test = train_test_split( |
可以看到分开后的数据集,顺序也被打乱,这样更有利于学习模型:
1 | print(y_train) |
建立模型-训练-预测
定义模块方式 KNeighborsClassifier(), 用 fit 来训练 training data,这一步就完成了训练的所有步骤, 后面的 knn 就已经是训练好的模型,可以直接用来 predict 测试集的数据, 对比用模型预测的值与真实的值,可以看到大概模拟出了数据,但是有误差,是不会完完全全预测正确的。
1 | knn = KNeighborsClassifier() |
完整代码:
1 | import numpy as np # 处理数据 |
sklearn 强大数据库
要点
eg: boston 房价, 糖尿病, 数字, Iris 花。
也可以生成虚拟的数据,例如用来训练线性回归模型的数据,可以用函数来生成。
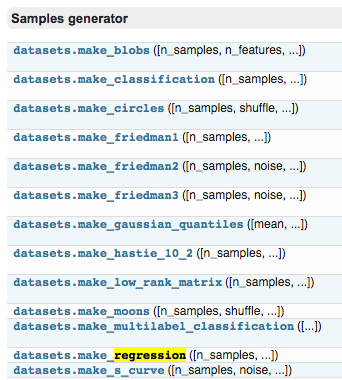
例如,点击进入 boston 房价的数据,可以看到 sample 的总数,属性,以及 label 等信息。
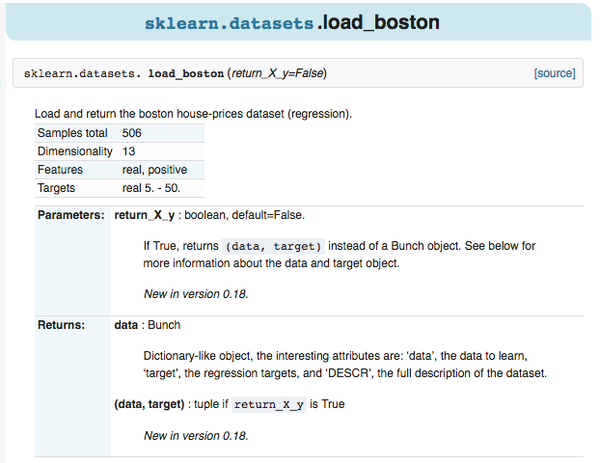
如果是自己生成数据,按照函数的形式,输入 sample,feature,target 的个数等等。
1 | sklearn.datasets.make_regression(n_samples=100, n_features=100, n_informative=10, n_targets=1, bias=0.0, effective_rank=None, tail_strength=0.5, noise=0.0, shuffle=True, coef=False, random_state=None)[source] |
导入模块
导入 datasets 包,本文以 Linear Regression 为例。
1 | from __future__ import print_function |
导入数据-训练模型
用 datasets.load_boston() 的形式加载数据,并给 X 和 y 赋值,这种形式在 Sklearn 中都是高度统一的。
1 | loaded_data = datasets.load_boston() |
定义模型。
可以直接用默认值去建立 model,默认值也不错,也可以自己改变参数使模型更好。 然后用 training data 去训练模型。
1 | model = LinearRegression() |
再打印出预测值,这里用 X 的前 4 个来预测,同时打印真实值,作为对比,可以看到是有些误差的。
1 | print(model.predict(data_X[:4, :])) |
为了提高准确度,可以通过尝试不同的 model,不同的参数,不同的预处理等方法,入门的话可以直接用默认值。
创建虚拟数据-可视化
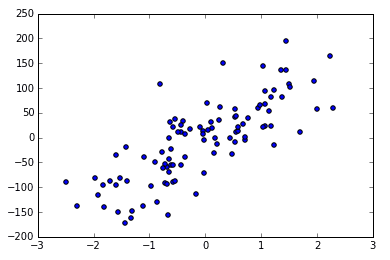
下面是创造数据的例子。
用函数来建立 100 个 sample,有一个 feature,和一个 target,这样比较方便可视化。
1 | X, y = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=10) |
用 scatter 的形式来输出结果。
1 | plt.scatter(X, y) |
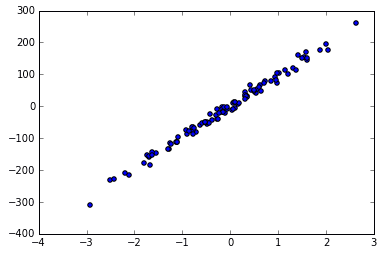
可以看到用函数生成的 Linear Regression 用的数据。
noise 越大的话,点就会越来越离散,例如 noise 由 10 变为 50.
1 | X, y = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=50) |
sklearn 常用属性与功能
上次学了 Sklearn 中的 data sets,今天来看 Model 的属性和功能。
这里以 LinearRegressor 为例,所以先导入包,数据,还有模型。
1 | from sklearn import datasets |
训练和预测
接下来 model.fit 和 model.predict 就属于 Model 的功能,用来训练模型,用训练好的模型预测。
1 | model.fit(data_X, data_y) |
参数和分数
然后,model.coef_ 和 model.intercept_ 属于 Model 的属性, 例如对于 LinearRegressor 这个模型,这两个属性分别输出模型的斜率和截距(与y轴的交点)。
1 | print(model.coef_) |
model.get_params() 也是功能,它可以取出之前定义的参数。
1 | print(model.get_params()) |
model.score(data_X, data_y) 它可以对 Model 用 R^2 的方式进行打分,输出精确度。关于 R^2 coefficient of determination 可以查看 wiki
1 | print(model.score(data_X, data_y)) # R^2 coefficient of determination |
代码:
1 | from sklearn import datasets |
正规化 Normalization
由于资料的偏差与跨度会影响机器学习的成效,因此正规化(标准化)数据可以提升机器学习的成效。首先由例子来讲解:
数据标准化
1 | from sklearn import preprocessing #标准化数据模块 |
数据标准化对机器学习成效的影响
加载模块
1 | # 标准化数据模块 |
生成适合做Classification数据
1 | #生成具有2种属性的300笔数据 |
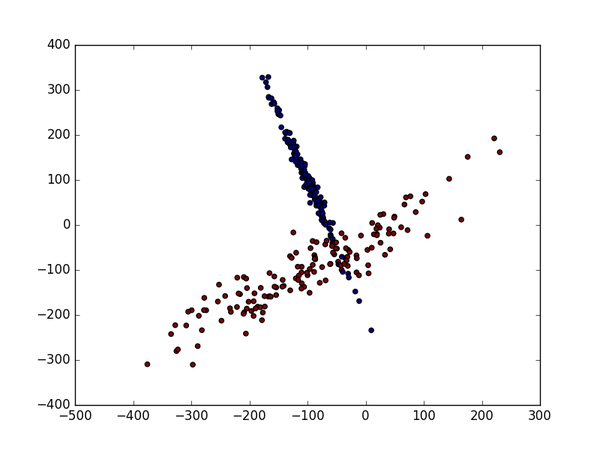
数据标准化前
标准化前的预测准确率只有0.477777777778
1 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) |
数据标准化后
数据的单位发生了变化, X 数据也被压缩到差不多大小范围.
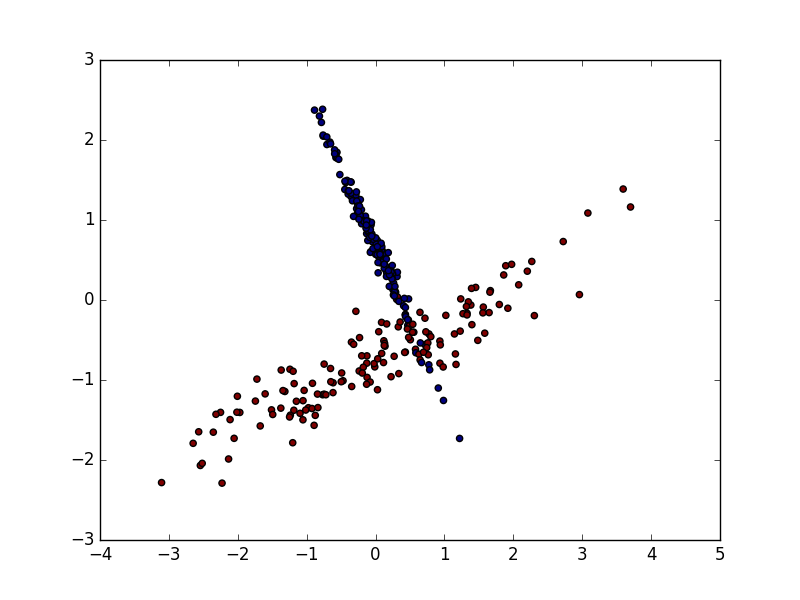
标准化后的预测准确率提升至0.9
1 | X = preprocessing.scale(X) |





